Data Engineering: Building the
Reliable Foundation for Your
Data-Driven Future
In today's economy, data is your most valuable asset. But like crude oil, its true value is only unlocked after it's been collected, refined, and delivered reliably. Data Engineering is the critical discipline that builds the high-performance "refinery" and "pipeline" for your business, transforming raw, chaotic data into the clean, trustworthy fuel required for analytics, AI, and intelligent decision-making.
What is Data Engineering? The Unseen Engine of Business Intelligence
Data Engineering is the specialized field focused on designing, building, and maintaining the systems and architecture that allow for the large-scale processing of data.
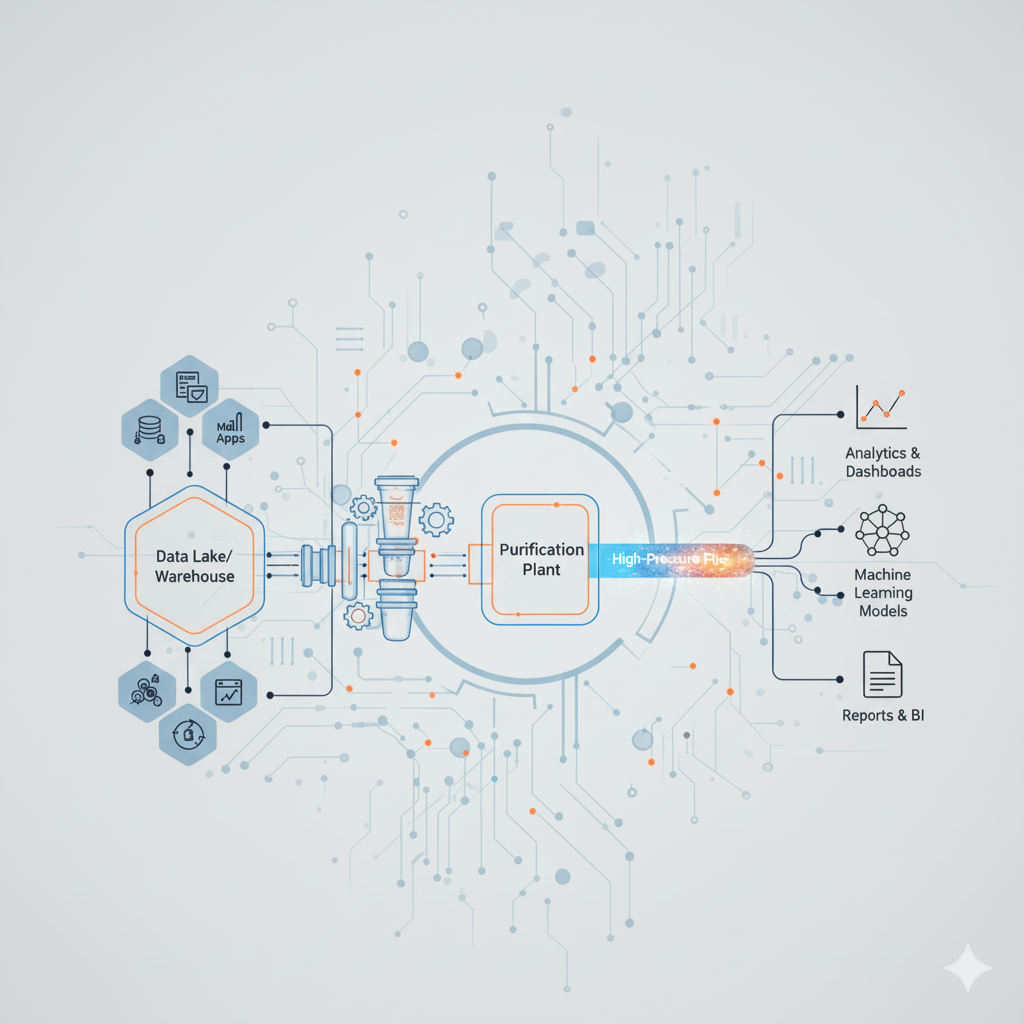
Think of it as the water supply system for a major city like Pune. You don't see the complex network of reservoirs, purification plants, and underground pipes, but you rely on it completely for clean, reliable water on demand.
Our Data Engineers are the architects of your data infrastructure. They build the:
Reservoirs (Data Lakes/Warehouses):
To safely store vast quantities of raw data.
Purification Plants (ETL/ELT Pipelines):
To clean, transform, and structure the data.
High-Pressure Pipes (Streaming Platforms):
To deliver that data reliably and instantly to where it's needed.
Without robust data engineering, your analytics and AI initiatives will fail to deliver on their promise.
The Consequences of a Weak Data Foundation
Does your organization struggle with any of the following?

Slow and Unreliable Reports:
Business teams waiting hours or days for critical reports that are often out of date.
Lack of Trust in Data:
Conflicting metrics and inconsistent data leading to a culture of second-guessing and manual verification.
Data Scientists Wasting Time:
Your analytics and AI talent spending 80% of their time finding and cleaning data instead of building models.
Inability to Scale:
Systems that work for a few gigabytes of data crumble under the terabytes of data you have today.
These aren't analytics problems; they are data engineering problems.
Our Data Engineering Services: From Architecture to Action
We provide end-to-end services to build a modern data stack that is scalable, reliable, and cost-effective.

Cloud / On-Prem Data Warehouse & Lakehouse Architecture
We design and implement centralized, scalable data platforms using best-in-class technologies like Apache Iceberg, S3, Minio, Snowflake, Databricks, etc. We architect for performance and future growth, whether you need a structured warehouse, a flexible data lake, or a unified lakehouse.

Modern ETL & ELT Pipeline Development
We build robust, automated data pipelines to move and transform your data. Using modern tools like UAP, dbt, Airflow, Fivetran, etc, we create efficient, maintainable, and well-documented ELT (Extract, Load, Transform) workflows that are the backbone of your data operations.

Real-Time Data Streaming and Processing
Enable up-to-the-second analytics and real-time applications. We build high-throughput streaming architectures using technologies like Apache Kafka, MQTT, Rabbit MQ, Spark Streaming, cloud-native services (like Kinesis and Pub/Sub), etc, to process data as it’s generated.
Data Governance and Quality Frameworks
Data is useless if it can't be trusted. We implement data quality checks, set up data catalogs for discoverability, and establish governance frameworks to ensure your data is accurate, secure, and compliant.
Our Technology Stack
We are pragmatic and tool-agnostic, but we have deep expertise in the modern data stack:









Why Partner with Us
